什么是Python爬虫?Python爬虫原理是什么?Python爬虫代码是如何实现的?码笔记分享Python介绍及爬虫原理详解:
什么是Python爬虫?
我们可以把互联网看成是各种信息的站点及网络设备在一起组成的一张蜘蛛网,这张网中什么信息都有,而我们上网就是获取互联网中信息内容的过程。
那么什么是爬虫?爬虫就是一段模拟人们上网的程序,爬虫可以抓取互联网上的信息,Python爬虫就是用Python语言写的一段爬虫程序。
Python爬虫抓取什么信息呢?想抓什么内容就抓什么内容,看用户如何自定义了。
Python爬虫的结构
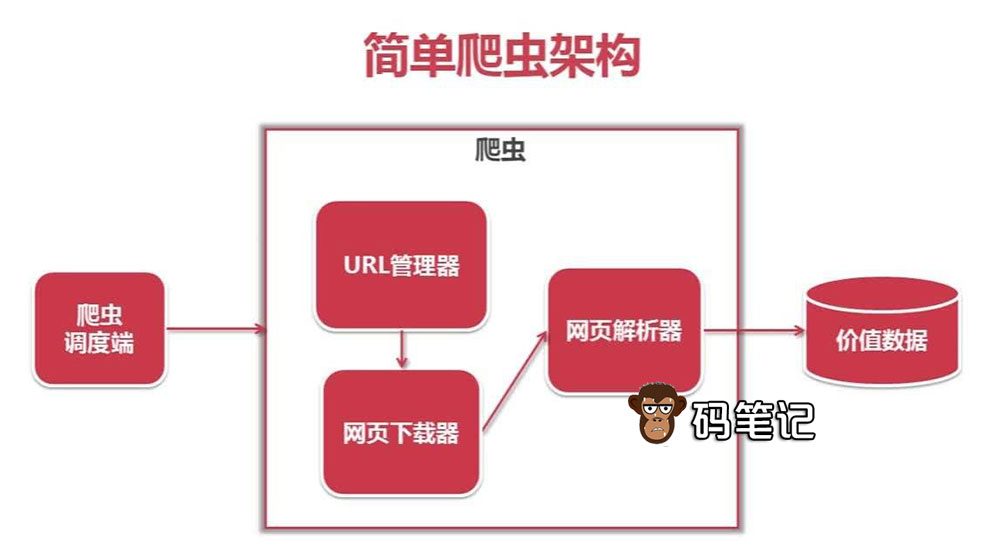
Python爬虫架构
Python爬虫主要是由5部分组成,即调度器、URL管理器、网页下载器、网页解析器、应用程序(应用程序用来爬取有价值数据),码笔记来详细介绍这5个组成部分的作用:
网页解析器有正则表达式、html.parser(Python自带)、beautifulsoup(第三方插件)、lxml(第三方插件),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
爬虫工作的基本流程
前面码笔记已经说了,爬虫就一段模拟用户上网并从互联网中获取信息的程序,码笔记来详细说下爬虫的工作流程:
人们正常上网过程:通过浏览器提交请求给网站服务器(打开浏览器输入网址或者通过搜索引擎搜索打开网址) --> 下载网页代码 --> 浏览器解析成页面 --> 用户浏览
爬虫爬取信息的过程:模拟浏览器发送请求获取网页代码 --> 按照代码设置提取有用的数据 --> 存放于数据库或文件中
详解Python爬虫的工作流程:
①Python爬虫程序使用http库向目标站点发起请求,即发送一个Request请求;
②服务器响应请求,爬虫会得到一个Response;Python爬虫通过正则表达式(RE模块)或者第三方解析库(例如:Beautifulsoup、pyquery)去解析HTML数据,使用JSON模块解析JSON数据;
③Python爬虫将数据保存到数据库(MySQL,Mongdb、Redis等)或者文件中。
云服务器租用优惠价格,2025年最新: